This article is Part 1 in a 7-Part Series.
- Part 1 - This Article
- Part 2 - How to calculate 17 billion similarities
- Part 3 - Independent code in performance optimizations
- Part 4 - Using bit masks for high-performance calculations
- Part 5 - Making bits faster
- Part 6 - Dividing a bit in two for performance
- Part 7 - Understanding OutOfMemoryException
Warning this post contains some math. Better still, it shows how to use it to solve real-life problems.
This post describes how I calculate similarity between recipes in my pet project cookit.pl. For those not familiar with it, cookit is a search engine for recipes. It crawls websites extracting recipes, then parses them and tries to create a precise ingredient list replete with amounts and units.
By the time of writing it had:
- 182 184 recipes
- 2936 ingredients
This scale may not seem huge, but trust me - It’s enough to bring a slew of problems to light. And that cookit runs on a crappy server, partly by choice, can make things all the more complicated.
Before turning to those problems, lets first answer this question:
How to calculate similarities?
The first question to ask is: How do you calculate similarity between two articles, recipes, objects in general ? Let’s use math! If object can be expressed as a series of ordered numbers (a vector) then there are many ways to express how two such vectors are similar to each other.
So how can a recipe be expressed as a vector? My answer was: If they have similar ingredients they are similar This means I have to create for each recipe, a vector of ingredients with 0 representing the lack of an ingredient and 1 its presence.
Similarity between recipes can now be expressed as the number of common ingredients (do an AND operation and count all the ones). So, case closed, right? Well, not exactly. This design has some problems.
Building a similarities vector
Let’s consider some cases where the initial idea will be too much of a simplification.
Taking similarity into account
Let’s take two recipes, one containing sea salt and the other salt. In a boolean representation, the similarity between them would be equal to zero. But they are actually similar, and can often be used interchangeably. So they are not the same but, they are similar. Now how to represent that?
I can take the advantage of the fact that all ingredients in cookit are organized in a graph. Where the child is more specific than the parent. For example, in this case, I have:
Spices -> solid spices -> mineral spices -> salt -> sea salt
We can use this knowledge to work and put all the parents and children into the vector as owned ingredients. The problem is, I then lose the significance of the actual ingredient used (meaning that sea salt for this recipe is ideal, and salt is just OK). The best way would be to use weights on how accurate the ingredient is for this recipe. So my vector will look like this:
| Spices | Solid spices | Mineral spices | Salt | Sea salt | |
|---|---|---|---|---|---|
Recipe with salt | (1*y)*y | (1*y)*y | (1*y) | 1 | (1*x) |
Recipe with salt(numbers) | 0.512 | 0.64 | 0.8 | 1 | 0.9 |
Recipe with sea salt | ((1*y)*y)*y | ((1*y)*y)*y | (1*y)*y | 1*y | 1 |
Recipe with sea salt(numbers) | 0.4096 | 0.512 | 0.64 | 0.8 | 1 |
where:
- x is in the range of 0-1 and is the penalty for being further away for children
- y is in the range of 0-1 and is the penalty for being further away for parents
Adding importance
Let’s take scrambled eggs made from these ingredients:
eggssaltpepper
And now a steak made from these:
meatsaltpepper
The current model would have us believe that those dishes are, at roghly in 66% similar. This is because every ingredient is given the same importance. The question now becomes, how do I calculate an ingredient’s importance? Easily, using the same idea Lucene did - the inverted index:
Sum of recipes having ingredient x / Sum of all ingredients in all recipes
Because salt and pepper are very popular ingredients, their weight will be very small. Because Meat and eggs are less popular, they will have a higher weight. This approach has the neat feature that it is normalized in zero to one range.
So, for now, the model looks good.
Calculating the vector
Let’s transfer all this knowledge into code:
float[] vector = new float[NUMBER_OF_ALL_INGREDIENTS]
foreach(var ingredient in recipe.Ingredients){
SetIngredientWeight(ingredient,vector,1);
}
private void SetIngredientWeight(Ingredient ing,float[] vector,float weight){
vector[ing.Id] = weight//set the weight for the current ingredient
foreach(var parent in ing.Parents)
SetIngredientWeight(parent,vector,weight*0.8) //go recursivly over each parent and add them with smaller weight
foreach(var child in ing.Children) //do the same for children
SetIngredientWeight(child,vector,weight*0.9)
}
What is happening:
I iterate over all the ingredients in the recipe and set the weight to 1. I then go recursively up and down the ingredient tree and set the weights for parents and children. The further away from the original ingredient, the less significant the ingredient is. So the weight is lowered (this is accomplished care by the weight*0.9 part in SetIngredientWeight)
This gives me a vector representation of every recipe. The “only” thing left is to figure a way to compare two vectors.
Calculating similarity
Ok, I have recipes represented as a vector of floats. Now, how does one go about converting two of those vectors into a single digit, from zero to one, representing how similar they are.
Luckily, mathematicians figured this long time ago:) There are many algorithms that can be helpful, but the most common, is to calculate the dot product. Hence it is there we shall start.
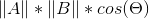
Let’s assume that our vectors are two-dimensional (this is like saying that every dish can be made from a combination of only two ingredients). They can then be drawn like this (image taken from Wikipedia):
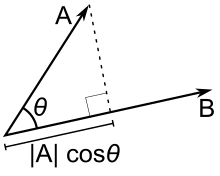
So what you’re looking at is one vector being projected onto another (the cosine part takes care of it). This gives its length relative to the other vector. However, relative values are nice but useless. Why? Because comparing the similarity of A and B to that of A and C would be to comparing the length of A projected onto B and A projected onto C. But the divisors are different, thus the comparison makes no sense. One way to deal with that is to normalize the value to one range (the most common being from zero to one). This is simple. Just divide the shorter vector, or projection, by the length of the longer projection.
As ComicStrip says:

Lets putting all of it into C#:
public float Similarity(Vector a, Vector b){
float accumulator=0;
for (int i = 0; i < a.Length; i++)
{
accumulator += b[i]*a[i];
}
var denom = Length(a)*Length(b); //convertion to absolute
return accumulator/denom; //convertion to absolute
}
where Length looks like this:
public float Length(Vector a){
return (float)Math.Sqrt(a.Sum(value => value*value));
}
So all well then? Far from it. But this will be the topic of the next post. Stay tune, rss, follow, or just don’t close to browser window ;)