The last time I described the hardware cookit is running on. Commonly referred as crap.
Now it’s time for some info what exactly is running on this fine pieace of hardware.
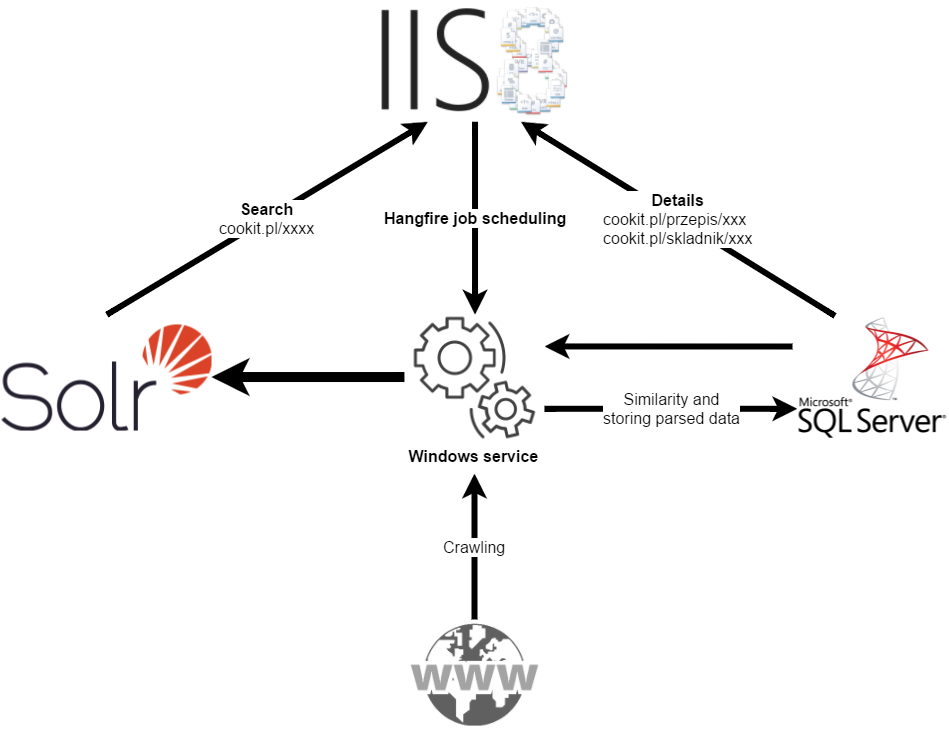
So, what is responsible for what?
-
The website - besides the obvious of serving the cookit.pl, it also hosts the admin panel and Hangfire dashboard. This part is almost read-only. Even the admin panel - all it does is schedule a Hangfire job and that’s it.
That idea stuck with me since reading a blog post about how reddit is architectured. And by the way it is a must read blog for anyone interested in how the big guys design their systems. -
Windows service In two words: Hangfire service.
Why the separation and not going the easy way of hosting Hangfire in the IIS process? Couple of reasons:
- Scaling - Building this way gives an easy way for horizontally (more machines with services) or vertically (more powerful machine hosting more workers)
- Autonomous - I can easily deploy one without the effect on the other.
- Very easy to debug - This may sound strange since debugging a Windows Service isn’t the nicest thing. But since all the Hangfire service is doing is executing a function in a class, the execution can be moved to a console application. It is supported by Hangfire and it just works. Simple as that.
- Resistent - The main process it hosts is crawling and parsing. And it used to crash a LOT. And I don’t mean throwing an exception and ending. Since it is highly parallel (hundreds of jobs) it used to create couple gigabyte log files, use so much processor that everything became unresponsive or just tried to allocate insane amount of memory and going down with a out of memory exception or stack overflow. And since the last ones can’t be caught after 5 such exceptions IIS stopped the whole pool, so the site was also down.
-
Ease of deployment - Few lines of PowerShell and that is it:
Stop-Service $serviceName
//replace the files
Start-Service $serviceName
- Full text search(Solr) - Searching (the no-brainer) and providing all the data for displaying the search results page.
- SQL Server - the single point of truth. Except one case:
-
Ingredients graph - while it may not seam as a equal building block as the above, it is. It fills a small problem where SQL databases suck. Modeling relations. I am talking a bit about this problem in my graph talk, but to show what I mean:
This is how sql displays subgraph of my ingredient graph:
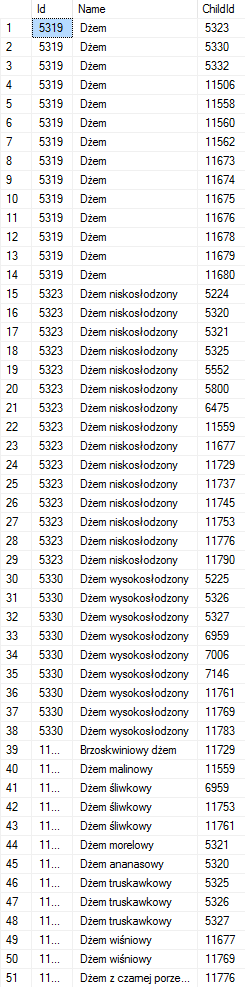
This view if great if You want to see data as numbers and values. For relations I prefer this (the same sub graph):
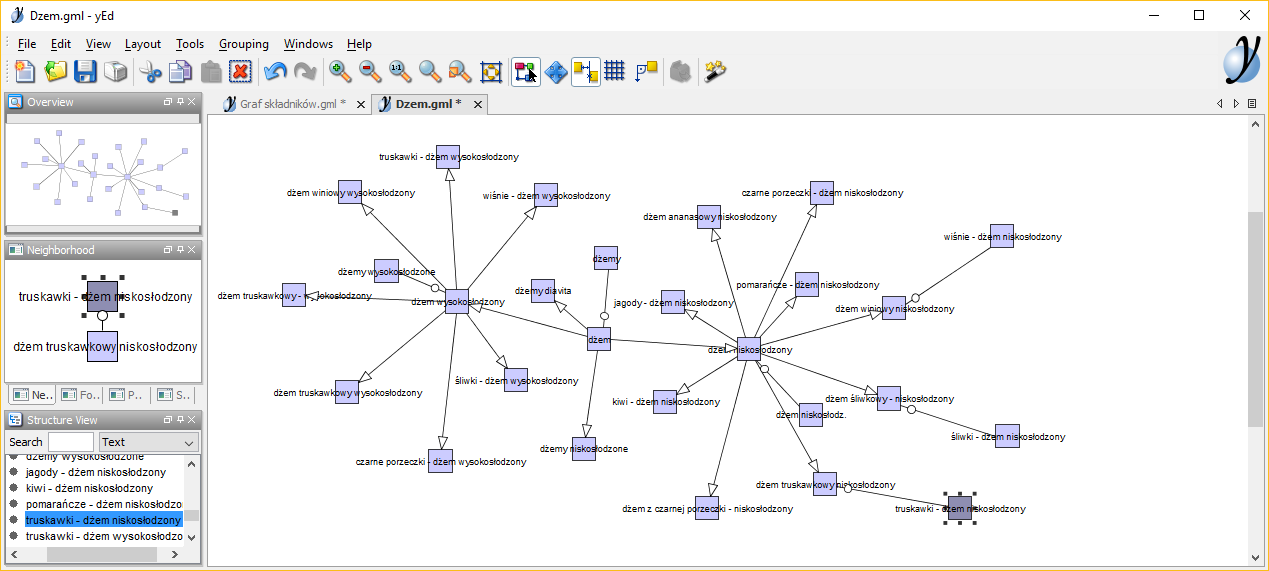
Meet yEd - a graph editing tool able of editing most graph files formats (mostly text files).
And while this data is being loaded into sql, this file is the point of truth.