This article is Part 3 in a 3-Part Series.
- Part 1 - What is the simplest database?
- Part 2 - Want unlimited scale and performance? This is where to start
- Part 3 - This Article
Previously I’ve wrote about key-value databases. They are awesome - ultra-fast, simple, can scale almost linear with the number of nodes. So why bother with complicating them?
Well, they have some issues.
Problems with key-value databases
The central concept of a key-value database is that the database doesn’t care what the is value. It may have some assumptions, like Redis, but the structure of the data is not of its interest. This leads to some limitations that can be problematic in some scenarios.
1. Can’t filter on value fields
Quite evident since from the database point of view value is a blob.
2. The whole value is returned
This may not seem as a problem, but remember, key-value databases are chosen for speed. When looking at a flow of retrieving data from a database:
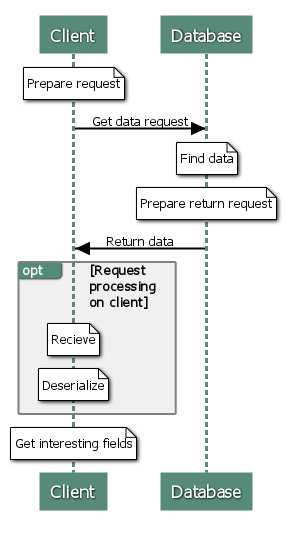
Most of the steps performance is dependent on the size of the transmitted data, not the data used (this is why SELECT * is a sign of someone not giving a f**k about performance).
3. The value can be updated only as a whole
It is a problem because we have to:
- get the complete data to the client (see point above)
- operate on the entire data
- send the whole data back to the database
Sounds not that bad, even good. We want to have the whole object when updating it, right?
Think about those cases:
- update users last login date
- append the element to the list (like online checkout basket)
- change the prices on certain products because of a promotion
So how to solve those problems and not loose all that speed?
Wide column databases
The idea behind it is simple:
Let's structure data (that is the value part) again into key-value pairs.
This is hat we have in key-value databases:

This is how wide column databases represent data:
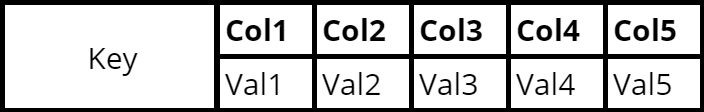
Having columns allows defining a subset of data we want to return to the client or subset of data that should be updated.
How is it different from a regular table in a relational database?
In most wide column databases, columns are defined on the single item level meaning there is no database-wide schema, which leads us to some interesting features of wide column databases:
Benefits from wide column databases
While wide column databases keep most of the perks of key-value databases mentioned previously they have some additional ones (They don’t have to exist in every implementation of a wide-column database, but most of them have it):
- partial operations (add column value, update column value).
- data compression. When dealing with sparse data we don’t have to store empty/null values. This way we can save space normally reserved because schema defined them.
- WHERE clause. This feature is not that common in this type of databases, but filtering on data starts to appear.
In the next post a sample domain modeling using a wide-column database.