This article is Part 2 in a 3-Part Series.
- Part 1 - What is the simplest database?
- Part 2 - This Article
- Part 3 - What is the problem with key-value databases and how wide column stores solve it.
The previous post laid out the most minimum requirements for something to be called a database. While they may be too bare bones for many, there are a lot of databases that don’t fulfill even half of them, and this isn’t stopping from using them on a daily basis.
The last time I’ve looked at files, this time something a bit more complex - key-value databases.
The idea
The idea behind key-value databases is very simple:
Store and retrieve objects based on a key.
So we are saying goodbye to:
- tables, columns or ant data typing - everything is a blob of some kind
- relations
- complex operations
We gave almost everything, what do we gain in exchange?
Why use a key-value database?
Speed
If You are thinking that getting the object from a key-value database is more or less the same as an index lookup in a relational database, keep on reading because You are very wrong, an order of big O wrong.
Indexes in relational databases are implemented using a B-Tree structure that looks like this:
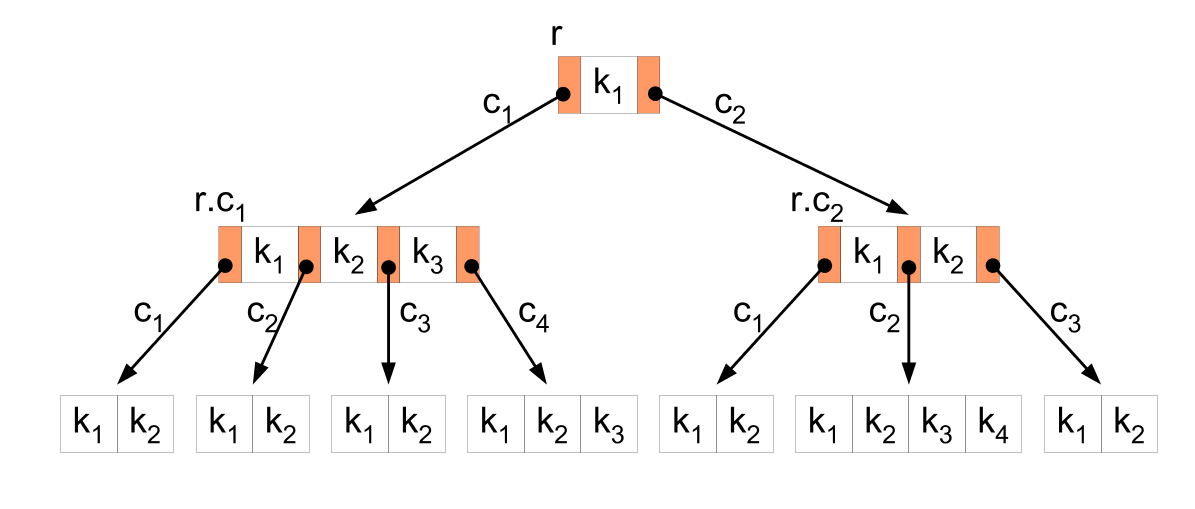
This is one of the most fundamental data structure in modern computer science. If You don’t know it please at least read this Wikipedia page. It will be a time well spend.
While this is a remarkable structure it has to obey the rules of mathematics when it comes to the cost of search:
O(log(n/m))
where:
- n - the total number of elements
- m - the number of items in a single node.
To contrast it, most key-value databases store the data in memory, so they can use a hashing function to determine the position of the element in the array. It’s cost is:
O(1)
You can’t get any better than this.
Simplicity
If something is simple it breaks less often, is easier to maintain and to reason about. Without this simplicity, we wouldn’t have the next point.
Horizontal scaling
When we introduce the following rules, that most key-value databases implement:
- the key is the only way to identify an item
- the hash function transforms the key into an integer in a deterministic way
- we aren’t doing any, or are limiting the scope, of aggregate operations
- update changes the whole value (since the database doesn’t know about the schema of the item). There are some databases that bypassed this rule. For more keep on reading.
Having those assumptions allow scaling such a solution horizontally easily. In the most simplistic way:
hash(key) % NUMBER_OF_SERVERS
While an oversimplification, but some key-value databases use it.
What not to expect from key-value databases
If You have been living in RDMS land here are some things not to look for in key-value databases:
Transactions
It is very rare to see them in key-value databases. Instead, we have atomicity. What is the difference?
- Atomicity - means that the operation will execute or not. In short, in the case of failure, we won’t end up with corrupted or partially changed data.
- Transactionality - a series of multiple operations that will execute atomicity as one.
Is the lack of transactions a problem? No. Let’s examine the cases when we would use them:
SELECT- no need for transactions. We ask for an element and get it back.-
DELETE- singleDELETEis atomic, so no problem here. The need could arrive when doing multiple deletes. This case boils down to the fact how did we get the keys of the elements to delete?- If we stored those keys as a value of another key - go to the
complex statements flows. - If we want to remove values, which keys fulfill some pattern then just retry the delete.
- If we stored those keys as a value of another key - go to the
UPDATE- the same as withDELETE.complex statements flows- the need for it happens when the value of one key contains keys that should be, for example, deleted. This means that there is a relation, and this means that we are trying to simulate an RDMS on top of a key-value database, and it’s not a good idea.
Examples
While those are very simple databases, they differ quite significantly. To show that let’s examine 3 most popular key-value databases according to db-engines.

Memcached
Designed for: cache
I’m starting from the third place and also from the oldest database in the ranking (initial release in 2003). Memcached is not exactly a database since its main feature involves auto deleting data. Think of it as a massive, fixed size, in memory cache. When there is no more memory available Memcached will start removing elements using the LRU algorithm. It starts deleting the least used values until it frees enough memory to store the new value. Memcached doesn’t have any option of persistence to disc, but let’s face it: there is no sense for persistence if the database can delete the data at any time.
Since Memcached is a cache store it has some limits on key and value sizes:
- key: up to 250 bytes
- value: up to 1MB
Let’s look at the must and should haves:
Must-haves:
- [-] ability to reliably persist data - Memcached will auto delete the oldest data, and we are talking about a database that stores everything in memory, so let’s not call it reliable persistence.
- [-] ability to reliably retrieve data - If the data wasn’t deleted it will be returned.
- ability to delete data - using delete command
Should-haves:
- [-] ability to query data - We can’t do any matching on keys.
- ability to update data - We can update the whole value. No partial updates.
- [-] has transactions - No the case in this databases.

Riak
Designed for: key-value database synchronized across multiple data centers
Riak, an implementation of Amazon Dynamo paper, is an entirely different beast than Memcached and was build to solve other problems. It is also the closes we get to a database in the classical definition. It’s a distributed, cross data center, persistent key-value database aiming for availability, even at the cost of consistency. The above statement contains a lot of information, so let’s decompose.
Data types
Key-value databases treat stored values as blobs, but some of them implement types that have a particular purpose and have separate API. In Riak case its:
Flags- true/false values. Can only be used inside a map type.Registers- named binaries. Also can only be used inside a mapCounters- as the number suggests incremented integers. Can be used in amapand as a value on its own.Sets- collection of binary values. Similar to the Counter type can be used on its own and in amap.Maps- collection of values. Differently than Sets they can contain other data types, even other maps.HyperLogLog- a probabilistic structure for checking cardinality of a set.
Clustering
Riak supports clustering with tunable consistency. How is it done? Since the cluster is a ring architecture, like this:
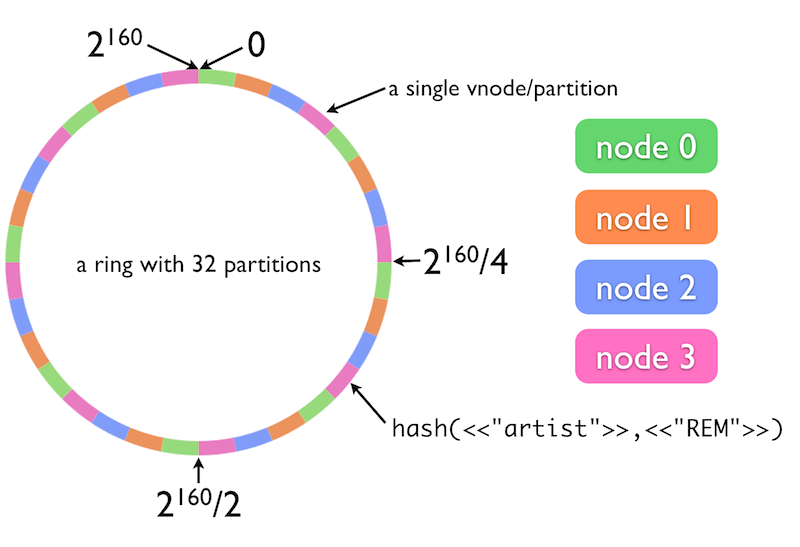
Tuning the level of consistency is done by defining how many nodes have to accept the operation before it’s confirmed (default is 3).
Riak goal from CAP is A, and it tries to achieve it by constructing a cluster where:
- nodes are organized in a ring
- there are no master nodes
- any node can accept writes for any key (no master node for a given hash value).
- allows concurrent writes on multiple machines for a single key.
All of the above lead to the need to handle conflict resolution resolution. Riak recommends using custom types whenever possible, but it will also work with blob values. Behavior when dealing with conflicts can be configured, and ranges from timestamp, last-write-wins to letting the client decide. One thing to note is that it’s not hard to find people complaining about Riak resurrecting deleted values even days after deletion.
Must-haves:
- ability to reliably persist data - This is one of the main points of Riak
- ability to reliably retrieve data - Since Riak consistency is tunable this point is also partly passed.
- ability to delete data - works, although resurecting deleted items is a reported problem.
Should-haves:
- [-] ability to query data - We can’t do any matching on keys, although it supports key searches using Solr.
- ability to update data - When using custom types they are possible. With blobs, no.
- [-] has transactions - No transaction support.

Redis
Designed for: speed
The number one should not be a shock to anyone. Redis is, as the full name suggests, a REmote DIctionary Server. Over the years it has grown a few functionalities, but it still is a memory key-value dictionary.
Architecture
Redis show that simplicity is speed. Important thing to note is that it is mainly an in-memory store with optional persistence:
- point in time snapshot
- Append Only File with async writes
- both of the above
Building upon the idea that everything is a string Redis exposes an interface for manipulating the values right on the database, without the need to send them to the client.
One last thing to note is that Redis has the option to write Lua scripts.
Data structures
Redis, similarly to Riak implements custom data structure, but nonstructured data is stored as a string, not as binary. Custom data structures are:
Binary-safe stringLists- collections of strings sorted according to the order of insertion (a linked list)Sets- collections of unique, unsorted strings.Sorted sets- similar toSetsbut every string has a score (a floating number). Elements are sorted by score, so unlikeSetsit is possible to retrieve ranges like top or bottom 10.Hashes- maps composed of fields associated with values. Both the field and the value are strings.Bit arrays- allows to set, clear, count and find the first set or unset bit.HyperLogLogs- the same as in Riak
Clustering
Redis is taking a different approach to clustering than the previous two:
- all nodes are connected
- values are automatically propagated to multiple servers
- has the concept of master and slave datasets
- it does not guarantee strong constistency, but it can be achieved using WAIT
- it if advised for the client to keep an up to date routing table of the cluster
- it can detect not responding and new nodes.
- nodes do not proxy requests. This means that if we request a key not present on the current node the server will return
MOVEDcommand to the client. - multi-node commands and Lua scripts are limited to near keys (no cross server operations)
- replication is asynchronous
- only one node accepts a write for a given key
Pub-sub
One feature that is unique to Redis, and to key-value databases in general (since it is not a database feature) is pub sub capability of Redis. With features as full cluster support and pattern matching for subscriptions, it is a first class citizen in Redis features and works quite well.
Must-haves:
- [-] ability to reliably persist data - This is not the main goal of Redis. Provided persistence options don’t give 100% certainty of data recovery in case of for example power failure.
- ability to reliably retrieve data - Redis has the notion of a master node for a given key and if we don’t mess with the routing table data will be returned reliably.
- ability to delete data - just works.
Should-haves:
- ability to query data - Redis exposes API to search for keys matching a pattern. What to note is it will return the keys, not the values.
- ability to update data - Works with custom types, and with blobs. Since everything is a string Redis provides string operations that are executed on the server and thus don’t require a round trip to the client.
- [o] has transactions - As Funbit and Alex pointed out, there are transactions in Redis. In Lua scripts and using the MULTI statement.
Comparison
| Option | Memcached | Riak | Redis |
|---|---|---|---|
| Key limits | 250 bytes | No limit | No limit |
| Value limits | 1 MB | No limit | 512 MB |
| Persistent | No | Yes | Optional |
| Transactions | No | No | Yes |
| Connection protocol | TCP/IP | HTTP | TCP/IP |
| Key scans | No | Done with Solr | Yes |
| Scripting | No | No | Yes(Lua) |
| Data schema | No | Custom types + blob | Custom types + blob |
| Data stored | binary | binary | string |
| Licence | BSD 3-clause | Apache 2 | BSD 3-clause |
| Cluster | |||
| Cluster info | Client knows all servers in cluster | Client knows some nodes | Client knows the routing table |
| Cluster architecture | share nothing | ring | all connected |
| Consistency | Doesn’t apply | Tunable from eventual to strong | No guarantee |
| Replication | No | Configurable | Async |
| Multi data center sync | No | Yes | Yes(only Enterprise version) |
| Run on | Windows/Linux/Unix | Linux | Windows/Linux |
| Main features | auto deletion of data | multi data center replication | speed/pub-sub |
| Build for | cache server | Key-value store across multiple data centers | speed |
Big thanks to Łukasz Pyrzyk for proofreading and pointing out some mistackes. Go check out his blog
Next, wide column databases.
Further reading:
- HyperLogLogs data structure - Wikipedia
- Very good analysys of HeyperLogLogs algorythm
- Redis cluster documentation
- Collision resolution
- Top Level analysys of Redis architecture and a conversation on Redis google group
- Riak reviews
- Most popular Key-value databases comparison on db-engines.com
- Very good Memcached Wikipedia page