This article is Part 4 in a 6-Part Series.
- Part 1 - Don't do it now.
- Part 2 - Don't do it now! Part 2. Background tasks, job queuing and scheduling with Hangfire
- Part 3 - Don't do it now! Part 3. Hangfire details - jobs
- Part 4 - This Article
- Part 5 - Don't do it now! Part 5. Hangfire details - job continuation with ContinueWith
- Part 6 - Don't do it now! Part 6. Hangfire details - recurring jobs and cron expressions
This part will cover few small topics:
- dashboard
- retries
- more technical part of the
Hangfire.BackgroundJobclass API - job cancellation
Dashboard
Let’s start with the administrative dashboard because it gives a good background for the rest of the post. It greets us with more or less this view: 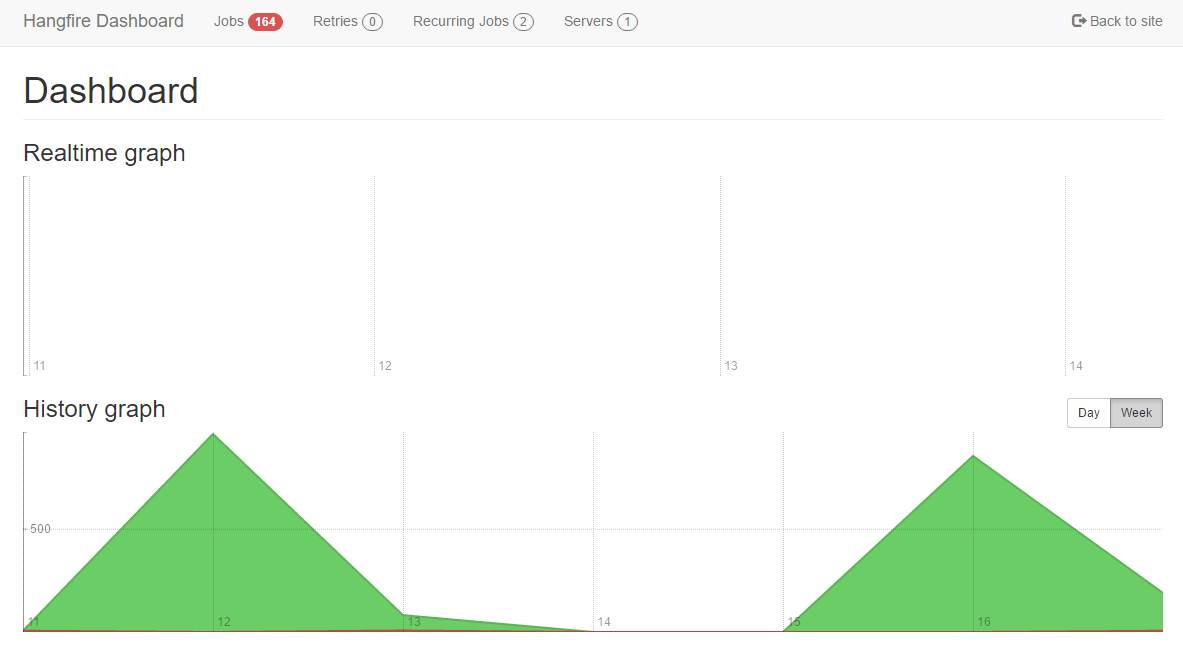 This is the main view of what the server is doing, and how well (are the jobs failing) The more interesting part is the next view:
This is the main view of what the server is doing, and how well (are the jobs failing) The more interesting part is the next view: 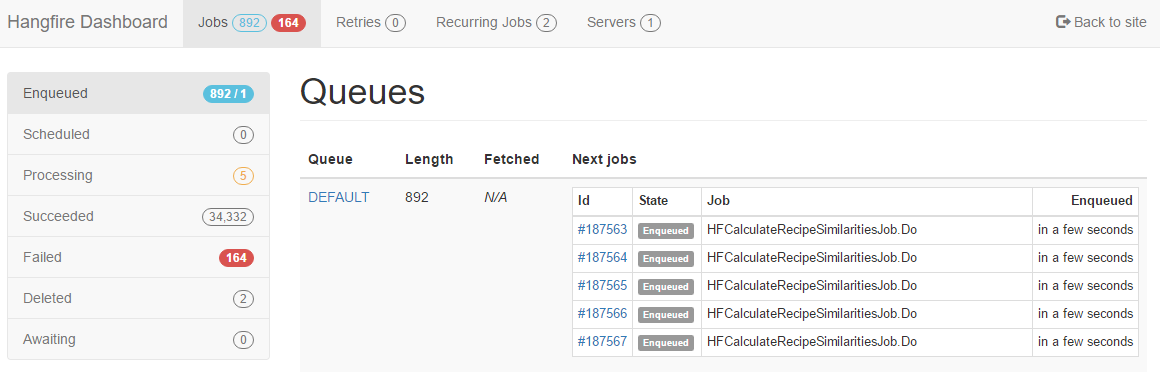 There’s a bit more detail about jobs in all states. They are self explanatory, maybe except the awaiting, but I will cover this in the next post. We can go as deep as the state of the specific job, which will look like this:
There’s a bit more detail about jobs in all states. They are self explanatory, maybe except the awaiting, but I will cover this in the next post. We can go as deep as the state of the specific job, which will look like this: 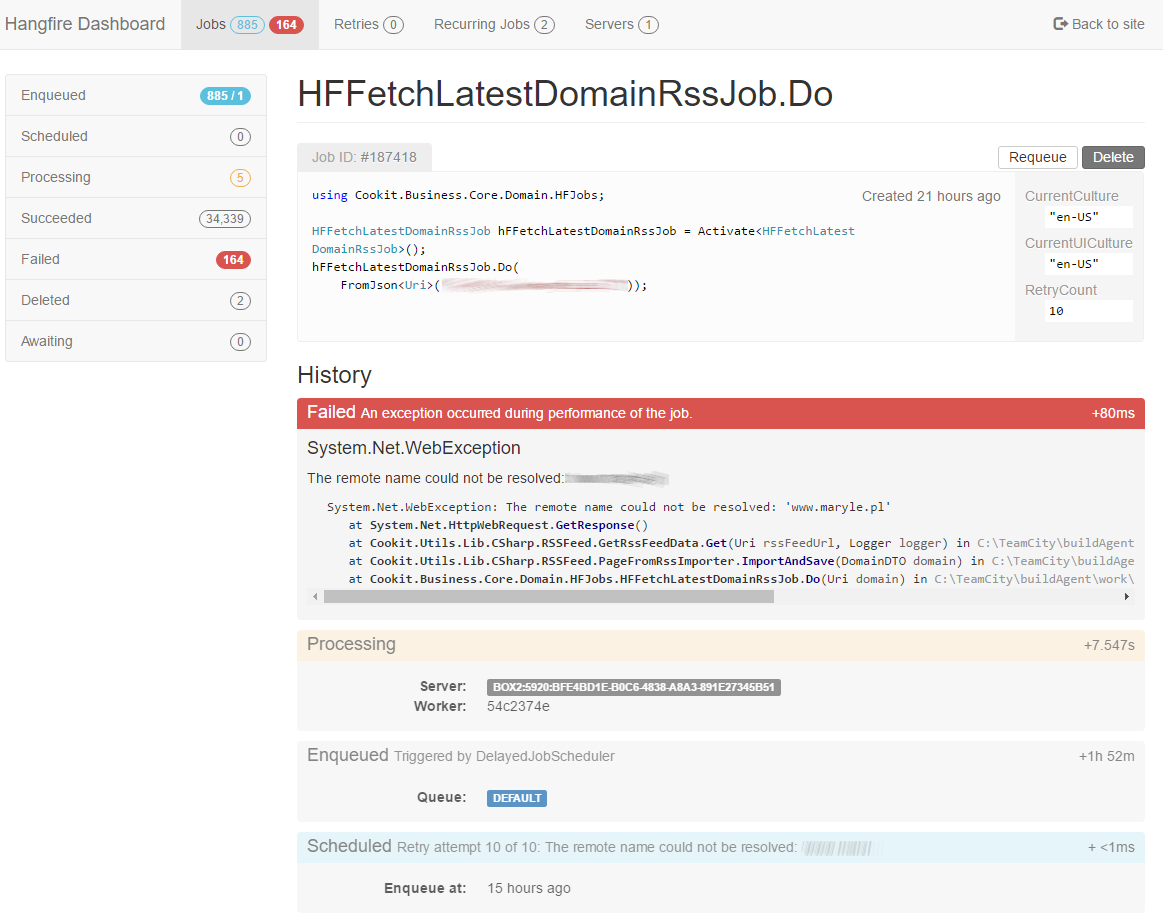
And this brings us to the main motives of this post:
- auto retries
- the ability to requeue a job
- the ability to delete a job
- job cancellation
Auto retry
This one is easy. Hangfire will auto retry every job that failed (timeouted or thrown an exception) configurable amount of times (10 by default). Each retry is an equivalent to normal enqueuing, so it lands at the end of the queue.
Manual requeue
This can be done in several ways:
- on the job page
- on the jobs page (allows requeuing multiple jobs).
- manually using
RequeuefromHangfire.BackgroundJob:
static bool Requeue(string jobId);
static bool Requeue(string jobId,string fromState);
Remember the unique job id returned by schedule methods from previous post? This is one of the places where it becomes useful. The overload has an additional parameter, fromState which is a fail switch. Job will be deleted only if it is in this exact state.
Delete a job
A similar story to requeuing. It can be done from the UI or with the API:
static bool Delete(string jobId);
static bool Delete(string jobId, string fromState);
No surprises here. The API is very similar as Requeue. This would seem to end the topic of Delete, but one very important question should pop into Your mind:
Just how does Hangfire delete a job?
This question becomes even more interesting when:
- we look at IJobCancellationToken in the documentation, which means cancellation is supported.
- we see that Hangfire is using
System.Threading.CancellationToken. - we take into account that
Delatemay be called from a different machine than currently executing the job.
Job cancellation
Cancellation can be triggered by two events (and both of the handle it differently):
1. Server shut down
When BackgroundJobServer(github), which is responsible for job execution, is being shut down, it stops processing new messages and triggers Cancel on its CancellationTokenSource. This token is used by the Worker(github) class to create the ServerJobCancellationToken (github) instance that will be injected into the method if it has a parameter of type IJobCancellationToken. Calling ThrowIfCancellationRequested on it, checks the token and throws OperationCanceledException. This exception is recognised as finishing due to issued cancellation. This way the server can gently close currently processing jobs.
2. Job deletetion (job cancellation)
Delete method uses the IBackgroundJobStateChanger (github), implemented by BackgroundJobStateChanger(github), to change the state of the job to Deleted and write it to storage. On this its responsibility finishes.
The rest of the cancellation logic is done in ThrowIfCancellationRequested in ServerJobCancellationToken(github)
public void ThrowIfCancellationRequested()
{
_shutdownToken.ThrowIfCancellationRequested();
if (IsJobAborted())
{
throw new JobAbortedException();
}
}
The first line is checking the CancellationToken mentioned in server shut down case. The second gets the job state from the database and checks if there were any state changes indicating whether it should be cancelled (like changing the state by calling Delete). If yes, JobAbortedException(github) exception is being thrown. This exception is handled in a very similar way as OperationCanceledException (from which it inherits) and also will be recognised as a indication of finishing due to issued cancellation.