Grafy,
czyli Neo4j w praktyce
Kto ja jestem?
- Architekt i TeamLeader w ITMAGINATION
- Zajmuję się systemami rozproszonymi i tym co można wywnioskować z danych
- No i można mnie spotkać na rekrutacji :)
- Po godzinach cookit.pl
- Bloguję na IndexOutOfRange.com
Agenda
- Modelowanie
- Cypher
- Profilowanie
- Administracja
- Wizualizacja
Modelowanie
Modelowanie
Co mamy do dyspozycji
Modelowanie
Typy w Property
- String, char
- Boolean
- byte, short, int, long
- double, float
- [] - tablice
Nie ma NULLi!
Modelowanie
Daty
Nie ma dat
A jak potrzebuję?
A po co Ci?
Do przechowywania? - long
Do wyszukiwania? - będzie później
Modelowanie
Property vs Node
{
"color":"blue"
}Properta
Typy wartościowe
Node

Typy referencyjne
Modelowanie
Property vs Node
Prosta zasada:
Chcę po tym szukać
Node
Chcę to zwracać
To po co to przechowujesz?
Properta
Modelowanie
Property vs Node
Statystyki:
- 10 nodów Color
- 1.001.000 nodów Node
- 1.001.010 nodów
- 1.001.010 relacji

Modelowanie
Property vs Node
MATCH (c:Color {name:"blue"})<--(n) RETURN count(n)MATCH (n:Node {color:"blue"}) RETURN count(n)5975ms
118 ms
Modelowanie
Symetryczne relacje


Modelowanie
Relacje bezkierunkowe


MATCH (a:Person)-[:IS_MARIED]-(b:Person)Modelowanie
Supernode
Modelowanie
Supernode
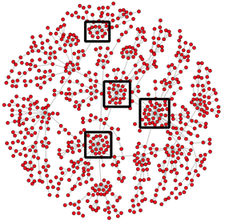
- Filtracja po czasie/typie
- Dodanie propert filtrujących
- Dodanie wag dla relacji
- Sharding z utrzymaniem kopii noda
- Własny resolver relacji
Modelowanie
Relacje z relacjami
Serwis do wyszukiwania biletów lotniczych

Modelowanie
Relacje z relacjami
Chcemy móc zawężać wyniki po linii lotniczej

Modelowanie
Relacje z relacjami
Wprowadzamy pośrednie wierzchołki

Modelowanie
Relacje z relacjami

Modelowanie
Kolejność
Pole określające kolejność
Listy

Modelowanie
Kolejność

Modelowanie
Kolejność

Modelowanie
Optymalizacja/Daty

Modelowanie
Optymalizacja/Daty
MATCH (timeline:Timeline{name:'timeline-1'})
-[:YEAR]->(y)
-[:MONTH]->(m)
-[:DAY]->(d)<-[:OCCURRED]-(n)
WHERE (y.value > {startYear} AND y.value < {endYear})
OR ({startYear} = {endYear})
OR (y.value = {startYear}
AND ((m.value > {startMonth})
OR (m.value = {startMonth}
AND d.value >= {startDay})
)
)
OR (y.value = {endYear}
AND ((m.value < {endMonth})
OR (m.value = {endMonth}
AND d.value <= {endDay})
)
)
RETURN n.name, (d.value + "-" + m.value + "-" + y.value) AS date;Modelowanie
Wypłaszczenie ścieżki

Cypher
Cypher
Składnia
MATCH- określa ścieżkę
WHERE- filtruje wyniki
RETURN- zwraca wyniki
WITH- łączy zapytania
(n:Node)- zmienna typu node
[r:RELATION]- zmienna typu relacja
p=(:Node)-[:LIKES]->(:Node1)- zmienna typu ścieżki
{ name:'value' }- property
()- node
[]- relacja
:TYPE:LABEL- określa typ/label
Cypher
Wzorce!
MATCH (n)-[r]->(m)
RETURN n,r,mMATCH (n:User)-[r:Likes]->(m:Movie)
RETURN n,r,mMATCH (n:User)-[r:Likes]->(m:Movie)
, (m:Movie)-[:DIRECTED_BY]->(p:Person {name:'Béla Tarr'})
RETURN n,r,m,pCypher
MATCH
MATCH (n:User) RETURN nMATCH (n) RETURN nDefiniuje ścieżkę/ścieżki
Filtruje ścieżkę
MATCH (n:User)-->(m) RETURN nMATCH (n:User)-[:LIKES]->(m) RETURN nMATCH (n:User)-[r:Likes]->(m:Movie)
, (m:Movie)-[:DIRECTED_BY]->(p:Person {name:'Béla Tarr'})
RETURN n,r,m,pCypher
OPTIONAL MATCH
MATCH (u:User)-[r:RATED]->(m:Movie)
OPTIONAL MATCH (u)-[FRIEND]->(p:Person)-[ACTS_IN]->(m)
RETURN u.login,m.title,p.nameMATCH (u:User)-[r:RATED]->(m:Movie)
OPTIONAL MATCH (u)-[FRIEND]->(p:Person)-[ACTS_IN]->(m)
-[DIRECTED]->(d:Director)
RETURN u.login,m.title,p.name,d.nameMATCH (u:User)-[r:RATED]->(m:Movie)
OPTIONAL MATCH (u)-[FRIEND]->(p:Person)-[ACTS_IN]->(m)
OPTIONAL MATCH (m)-[DIRECTED]->(d:Director)
RETURN u.login,m.title,p.name,d.nameDopasowanie całej ścieżki
Dopasowanie osobnych ścieżek
Cypher
UNION
UNION
UNION ALL
MATCH (u:User)
RETURN u.login as name
UNION
MATCH (p:Person)
RETURN p.name as name
MATCH (u:User)
RETURN u.login as name
UNION ALL
MATCH (p:Person)
RETURN p.name as name
Cypher
WITH
MATCH (n:User)-[:RATED]->(m:Movie)
WITH n,count(m) as ratedMovies
ORDER BY ratedMovies DESC
MATCH (n:User)-[:FRIEND]->(f:Person)
WITH n,ratedMovies,count(f) as friendedPeople
RETURN n.login,ratedMovies,friendedPeople- Agregacja
- Pipowanie zapytań
Cypher
SKIP/LIMIT
LIMIT
MATCH (p:Person)
RETURN p
LIMIT pSKIP
MATCH (p:Person)
RETURN p
SKIP 10
LIMIT 20
Cypher
REMOVE/DELETE
REMOVE - do Label
MATCH (p:Director)
WHERE not (p)-[:DIRECTED]->(:Movie)
REMOVE p:DirectorDELETE - do nodów
MATCH (p:Director)
WHERE not (p)-[:DIRECTED]->(:Movie)
DELETE pCypher
Relacje
MATCH p=(d:User)-[*]-(f:Director)
RETURN nodes(p)
Limit 20nodes
MATCH p=(d:User)-[*]-(f:Director)
RETURN length(p)
Limit 20length
MATCH p=(d:User)-[*]-(f:Director)
RETURN relationships(p)
Limit 20relationships
Cypher
Tablice
MATCH (b:Book)
WHERE ANY (tag IN b.tags WHERE tag IN ['nosql','neo4j'])
RETURN t.name,b.tagsOperatory: ANY, ALL, NONE, SINGLE
MATCH (b:Book)
WHERE ANY (tag IN b.tags WHERE tag = 'nosql')
AND NONE (tag IN b.tags WHERE tag = 'neo4j')
RETURN b.title, b.tagsCypher
Tablice /|
MATCH (p:Project)
FOREACH (t IN p.tag |
MERGE (tagNode:Tag{value:t})
MERGE (project)-[:TAG]->(tagNode))
REMOVE p.tagPipowanie operacji na kolekcjach
Cypher
Tablice /FILTER
RETURN FILTER (x IN [1,2,3,4] WHERE x%2=0)Filtracja elementów zwracanych kolekcji
MATCH p= (e)-[*]->(a:Movie)
WITH p
LIMIT 10
RETURN FILTER (node IN nodes(p) WHERE node:Person)Cypher
Tablice/FOREACH
MATCH p=shortestPath( (a:User)-[*]-(b:Director) )
FOREACH (n IN nodes(p) | CREATE (n)-[:USER_TO_DIRECTOR]->(b))Cypher
Tablice/COLLECT i EXTRACT
MATCH (p:Person)-[:RATED]->(m:Movie)
RETURN p.name,collect(m.title)COLLECT - zamiana w tablicę
MATCH path=(p:Person)-[:RATED]->(m:Movie)
RETURN EXTRACT(node in nodes(path) | Labels(node))EXTRACT - zamiana w elementy
Cypher
Parametry
MATCH (n:User)-[r:Likes]->(m:Movie {MovieName:{name}})
RETURN n,r,mMATCH (n:User)-[r:{Type}]->(m:Movie)
RETURN n,r,mNie OK:
OK:
Cypher
REDUCE
MATCH p= (e)-[*]->(a:Movie)
WITH p
LIMIT 10
RETURN REDUCE (path="START", i IN nodes(p) | path +"->"+head(labels(i))) as TextRETURN REDUCE (total = 0, i in [1,2,3] | total + i)Cypher
Refcard
http://neo4j.com/docs/cypher-refcard/current/
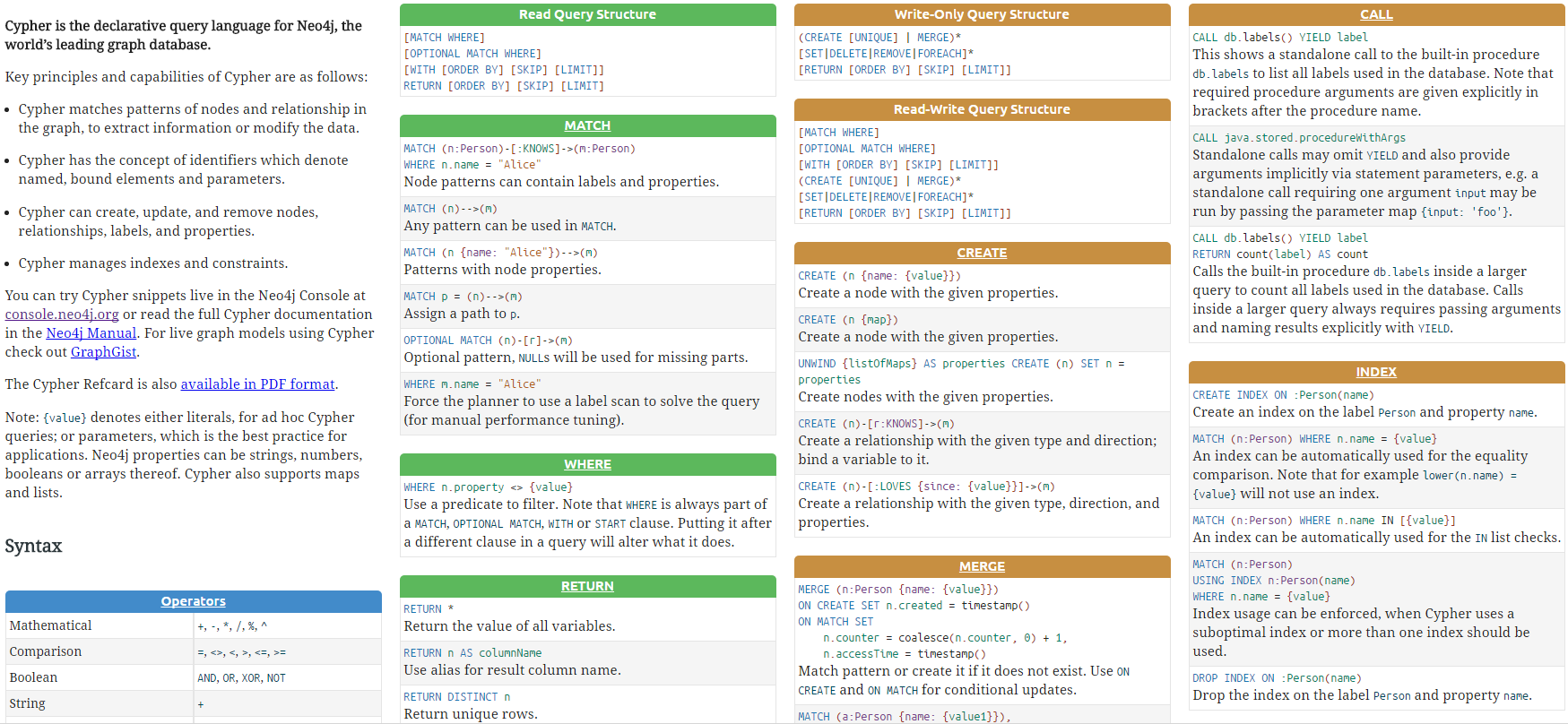
Cypher
Procedury/APOC
APOC(Awesome Procedures On Cypher)

CALL apoc.help("apoc")- Uzupełnienie Cyphera
- Funkcje Javowe
- 194 funkcje
Cypher
Procedury/APOC
- Obsługę indeksów
- Tworzenie meta grafów
- Eksport/import z jsona (bazy relacyjne,CSV,JSON, HTTP)
- Integracja z Elastic
- Monitoring
- Joby
- Operacje Gisowe
- Metody kolekcji
- Stemming
- Daty!
- Dodatkowe algorytmy grafowe
Cypher
Gremlin/Apache TinkerPop

g.V().has("name","gremlin")
.out("knows")
.values("name")Cypher - profilowanie
Cypher - profilowanie
Proces/Parser
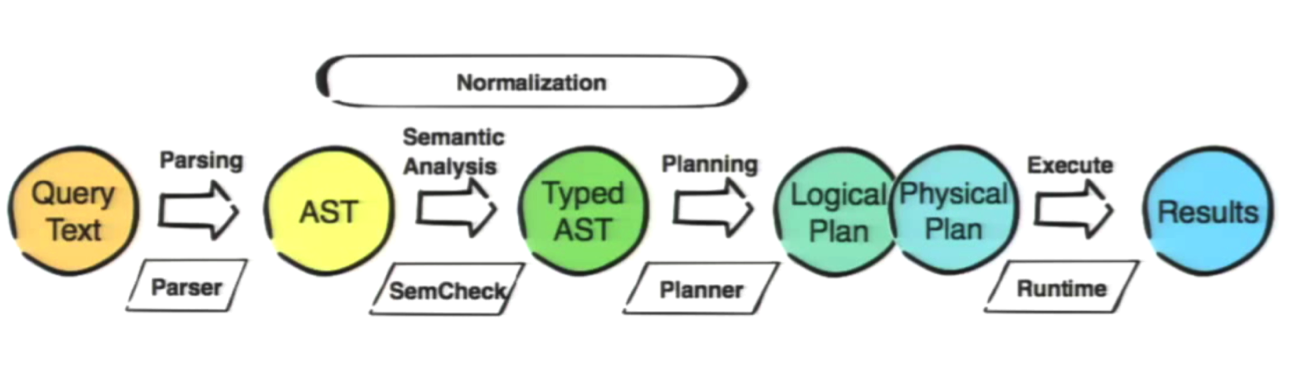
Tworzenie AST
Normalizacja AST
Błędy składniowe
Cypher - profilowanie
Proces/SemCheck
Błędy w typach
Cypher - profilowanie
Proces/Logical plans
Tworzenie wielu planów logicznych wykonania zapytania
Szacowanie kosztów i zysków operacji logicznych
Dobór indeksów
Cypher - profilowanie
Proces/Physical Plan
Podobny do wybranego planu logicznego
Zawiera natywne operatory
Cypher - profilowanie
EXPLAIN/PROFILE
EXPLAIN - szacuje, nie wykonuje
PROFILE - szacuje, wykonuje
Prefixy do komend
Abstrakcyjna jednostka operacji db hit
Cypher - profilowanie
EXPLAIN/PROFILE
- All nodes scan
- Label scan
Operatory:
- Node index seek
- Node index scan
Cypher - profilowanie
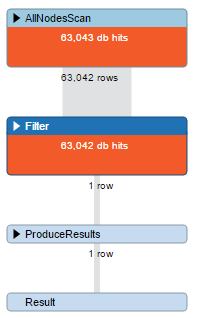
Optymalizacja
MATCH (movie {title:"The Matrix"})
RETURN movieMATCH (movie:Movie {title:"The Matrix"})
RETURN movieCREATE INDEX ON :Movie(title)
CREATE INDEX ON :Person(name)Cypher - profilowanie
Indeksy
Wykorzystywane tylko do znalezienia startowego punktu
Cypher - profilowanie
Optymalizacja
MATCH (movie {title:"The Matrix"})
RETURN movieMATCH (movie:Movie {title:"The Matrix"})
RETURN movie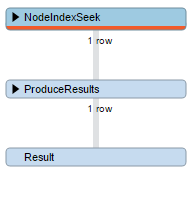
Cypher - profilowanie
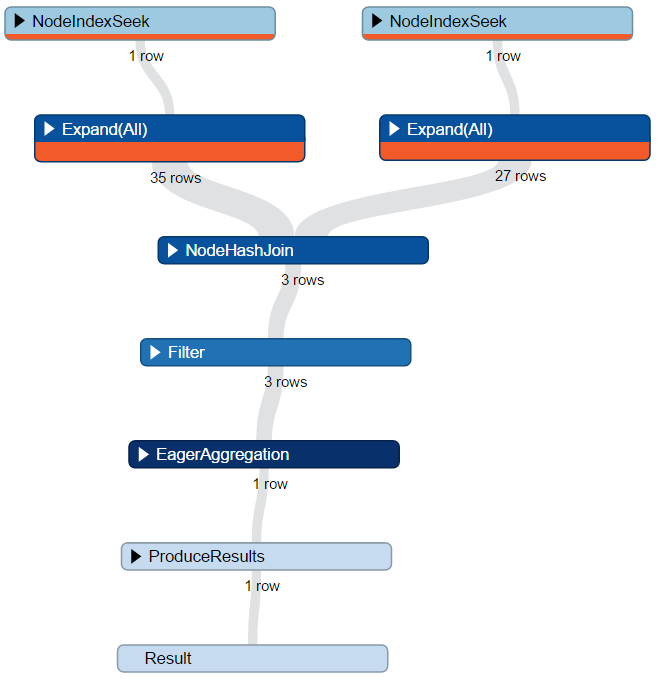
Hinty USING
MATCH (a:Person {name:"Tom Hanks"})-[:ACTS_IN]->
()<-[:ACTS_IN]-(b:Person {name:"Meg Ryan"})
RETURN count(*)MATCH (a:Person {name:"Tom Hanks"})-[:ACTS_IN]->
()<-[:ACTS_IN]-(b:Person {name:"Meg Ryan"})
USING INDEX a:Person(name)
USING INDEX b:Person(name)
RETURN count(*)Średnio:
Lepiej:
Cypher - profilowanie
Hinty USING

Cypher - profilowanie
Rozbicie kwerendy
MATCH (a:Person {name:"Tom Hanks"})-[:ACTS_IN]->
(m1)<-[:ACTS_IN]-(coActor)-[:ACTS_IN]->(m2)
RETURN distinct m2.titleMATCH (a:Person {name:"Tom Hanks"})-[:ACTS_IN]->
(m1)<-[:ACTS_IN]-(coActor)
WITH DISTINCT coActor
MATCH (coActor)-[:ACTS_IN]->(m2)
RETURN distinct m2.titleŚrednio:
Lepiej:
Cypher - profilowanie
Rozbicie kwerendy
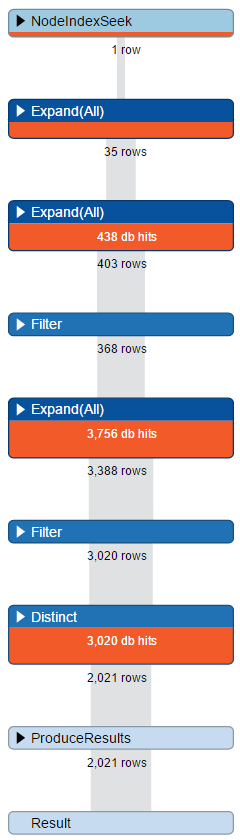
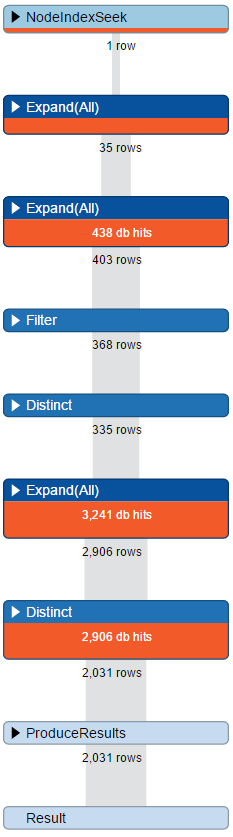
Cypher - profilowanie
Wymuszenie SCAN
MATCH (a:Actor)-->(m:Movie:Comedy)
RETURN count(distinct a)MATCH (a:Actor)-->(m:Movie:Comedy)
USING SCAN m:Comedy
RETURN count(distinct a)Cypher - profilowanie
Wymuszenie SCAN

Cypher - profilowanie
Iloczyn kartezjański
MATCH (a:Actor),(m:Movie)
RETURN count(a),count(m)MATCH (a:Actor)
WITH count(a) as actorCount
MATCH (m:Movie)
RETURN actorCount,count(m)Bardzo źle:
Dobrze:

Cypher - profilowanie
Dobre praktyki
Warunki w MATCH, nie w WHERE
Zawężanie startowych nodów
Indeksy dla startowych nodów
Agregaty i distinct - z uwagą
Określanie kierunku relacji.
Czyli -[]-> a nie -[]-
Lepiej wiele MATCH zamiast jednego
Tuning
Tuning
Neo4j/Storage
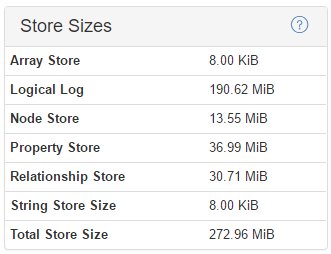
:play sysinfo
Tuning
Neo4j/Mapped files
Co to są memory mapped files?
neostore.nodestore.db.mapped_memory
neostore.relationshipstore.db.mapped_memory
neostore.propertystore.db.mapped_memory
neostore.propertystore.db.strings.mapped_memory
neostore.propertystore.db.arrays.mapped_memoryPamiętaj o stosie Javy!
Tuning
Neo4j/Block size
Co to jest block size?
label_block_size
array_block_size
string_block_size
Czemu mam się tym przejmować?
node_auto_indexingAuto indeksacja
Tuning
Neo4j/Cache
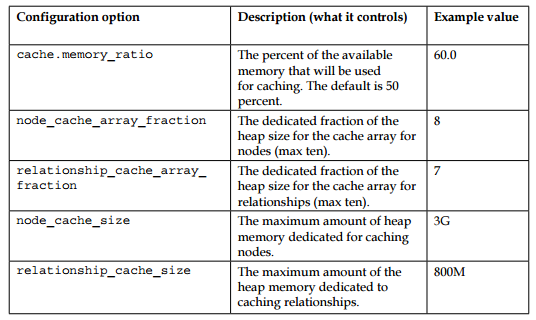
Tuning
Linux
Zwiększyć ulimit
Ustawić use_memory_mapped_buffers na true
Tuning
Ustawienia - JVM
GC:
- Copying collector (default)
- -XX:+UseConcMarkSweepGC
- -XX:+UseParallelGC (dla stosu >10GB)
Java options:
- -server flag
- Xmx - max pamięci
- Xms - min pamięci
Reszta: http://www.oracle.com/technetwork/articles/java/vmoptions-jsp-140102.html
Tuning
Heap/Transaction size
jvmtop(https://github.com/patric-r/jvmtop)
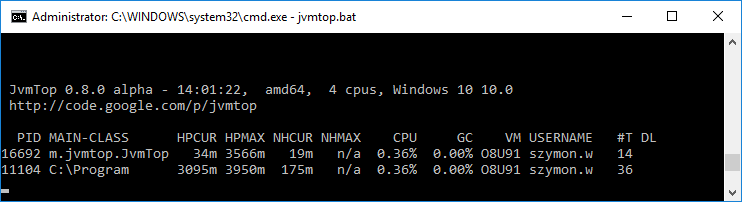
Możliwość monitorowania jednego procesu
(jvmtop.bat <pid>)
Tuning
Heap/Transaction size
jvisualvm(https://visualvm.java.net)
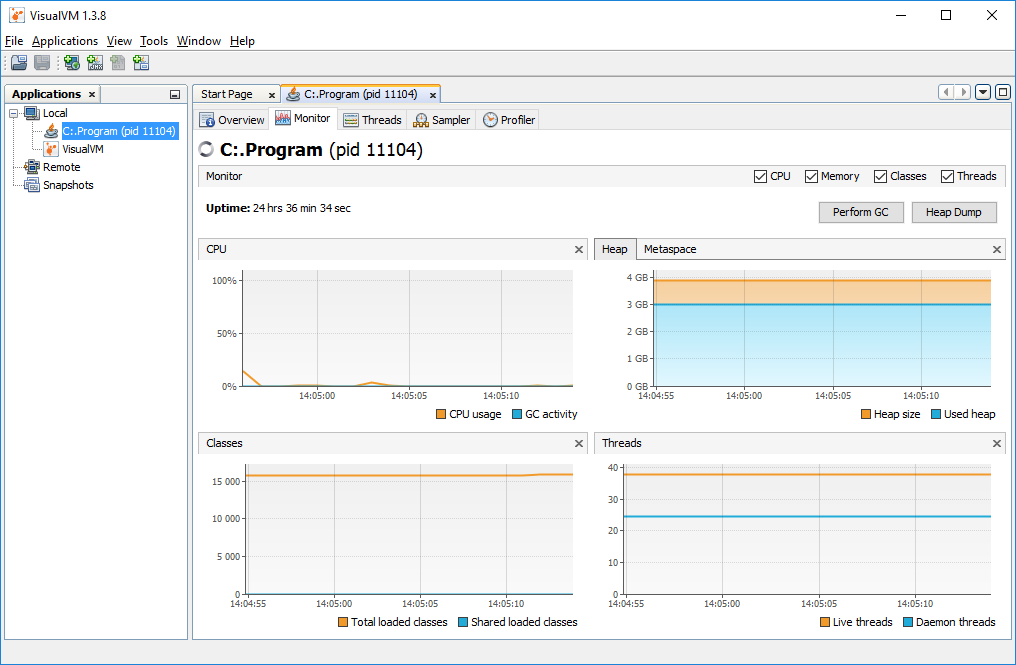
Tuning
Embedded mode vs server mode
Trochę historii
Porównanie
| Co | Embedded | Server |
|---|---|---|
| 1 Tx per node (1,000,000 x 1) | 168,815 ms (5,952 nodes/sek) |
2,380,140 ms (420 nodes/sek) |
| 1 Tx (1 x 1,000,000) | 25,654 ms (40,000 nodes/sek) |
- |
| (20 x 50,000) | 16,081 ms (62,500 nodes/sek) |
148,357 ms (6756 nodes/sek) |
Tuning
Server mode
Tuning
Server mode
REST - Transakcja (domyślnie)
Transakcja - wątek
Bolt
Pluginy
Tuning
Server mode/Server plugin
Deployment przez umieszczenie w katalogu
Widoczny poprzez url
Dziedziczenie po SeverPlugin
Ma dostęp co corowego API
(jak w embeded mode)
Tuning
Server mode
/Unmanged extensions
Deployment przez umieszczenie w katalogu
+ wpis w configu
Widoczny poprzez url
Nie musimy po niczym dziedziczyć
Dostaje bazę jako dependency
Template (https://goo.gl/JZylMb)
Tuning
Server mode
/Rozszerzenia porównanie
| Co | Liczba operacji | curl | Klient |
|---|---|---|---|
| REST API | 602 | 5303ms | 917ms |
| Cypher | 1 | 45ms | 32ms |
| Server plugin | 1 | 20ms | 16ms |
| Unmanaged extension | 1 | 20ms | 18ms |
Tuning
Embedded mode
Tuning
Embedded mode
Możliwość określenia typu trawersacji
- Breadth first (domyślny)
- Depth first
- A*,....
Customowy trawerser
Customowy resolver krawędzi
Wywołania funkcji
Indeksy
Indeksy
Typy
Manualne (Lucene)
Auto indexes
Schema indexes
Indeksy
Manualne(Legacy)
Pierwsze indeksy w Neo4j
Na bazie Lucene
Zarządzane całkowicie przez API
Nie ma update
Nie mają pojęcia o labelach
Mogą być full textowe
Mogą operować na wielu propertach
Można przekazać dodatkowe opcje
(http://goo.gl/haLQpp)
Mogą indeksować relacje
Indeksy
Manualne(Legacy)
Wywołanie w Cypher:
Wywoływanie w cypher ze składnią Lucene:
Zarządzanie w Cypher poprzez:
start n=node:users("name:John Johnson")
return nstart n=node:users(name="John Johnson")
return ncall apoc.index.*Indeksy
Auto indexes
Od wersji 1.4
Pod spodem to manualny indeks
Mogą dotyczyć nodów i relacji
Włączenie w configu:
- node_auto_indexing=true
- relationship_auto_indexing=true
Jeden dla całej bazy
Indeks jest dla property
Indeksy
Schema indexes
Asynchroniczne
Automatyczne
Mogą mieć tylko jedno pole z labela
Tworzenie:
CREATE INDEX ON :Person(name);
Niszczenie:
DELETE INDEX ON :Person(name);Tworzenie:
CREATE INDEX ON :Person(name);
Niszczenie:
DELETE INDEX ON :Person(name);Indeksy
Constrainy
Tworzenie constrainów
CREATE Constraint on (node:Person)
ASSERT node.name IS UniqueUsuwanie
DROP Constraint on (node:Person)
ASSERT node.Name IS UNIQUEIndeksy
Administracja
schema - listuje indeksy
schema -l :Person -p INDEX_NAME - stan indexu INDEX_NAME
opcje:
- l - wszystkie indeksy na labelu
- p - indeksy na propercie
- v - błędy jeżeli indeks jest w błędnym stanie
CALL apoc.index.list()Lista indeksów:
neo4j-shell (od 3.0 tylko Linux)
Administracja
Administracja
Backupy
Community Edition
- offline (kopiowanie plików ręcznie)
Enterprise Edition
- online (bez wyłączania bazy)
- full
- incremental
Administracja
High Availability
Klastrowanie
Master + many slaves
Master - read/write
Slave - read
PAXOS - wyłanianie mastera
Slave - pełna kopia
Administracja
DataReplication
Asynchroniczna replikacja (by default)
Ustawienia:
- ha.pull_interval - jak często slave pyta mastera (sek)
- ha.tx_push_factor - ilość slavów potwierdzających commit zanim master wyśle commit (0 - asynchronicznie)
- ha.tx_push_strategy - fixed/round robin. Wybór slavóow do których wypychane są dane.
Wizualiacja
http://volkanpaksoy.com/archive/2015/02/19/visual-tools-for-neo4j/
Vizualizacja
Linkurious
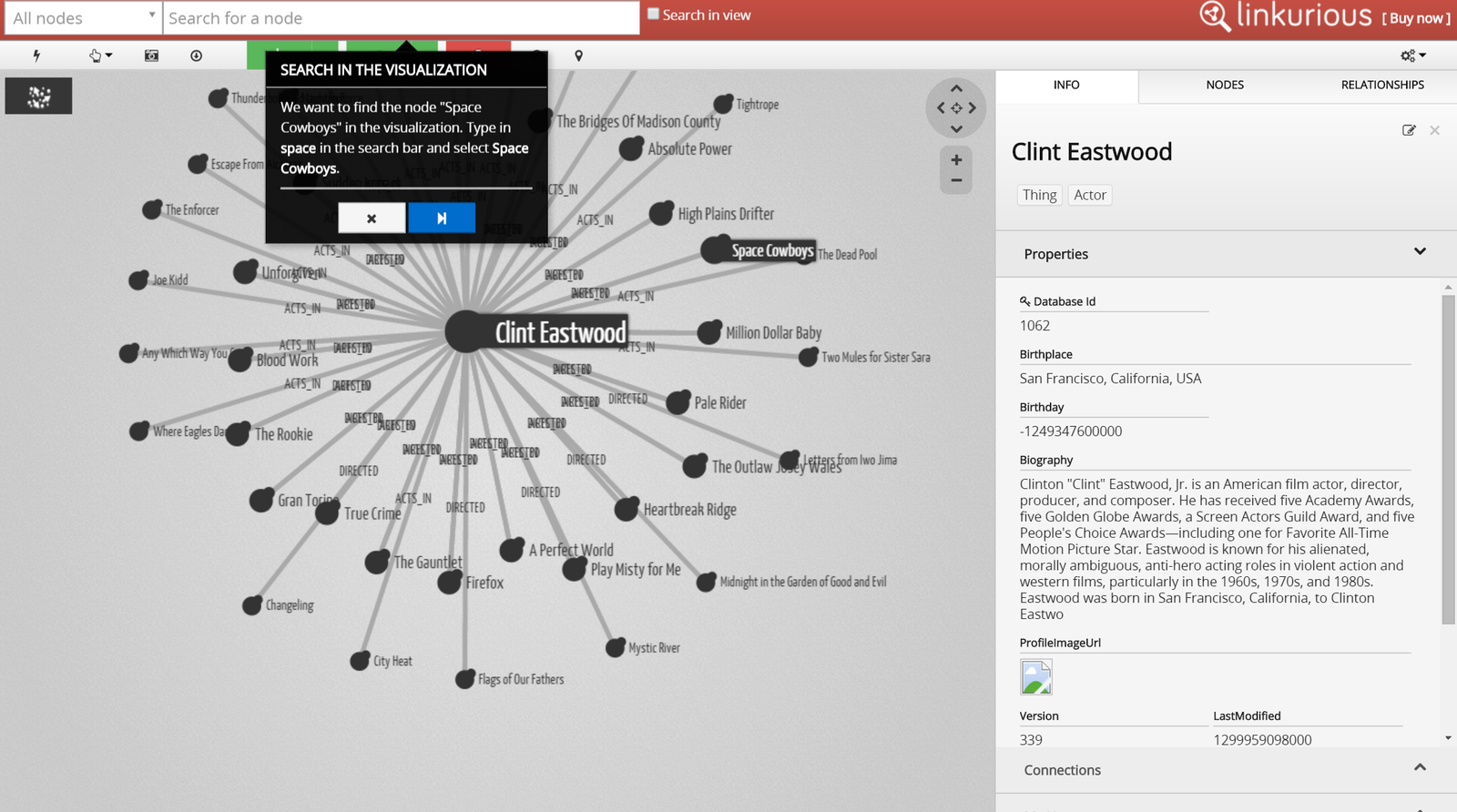
Vizualizacja
Gephii yEd
Dema
Różne
Książki
Program dla startupów
Koniec
